
Mahzarin Banaji Is Probing the Black Box of LLMs
Psychology Is Everywhere

In early 2023, Mahzarin Banaji was meeting with her student Tessa Charlesworth (who is now at Northwestern University) when the topic of ChatGPT arose. Banaji had heard of the tool but hadn’t yet engaged with it. The two decided to do a quick experiment while they set up for their meeting.
“I said, ‘Ask GPT: What are your implicit biases?’ Because what else was I going to ask?” Banaji said.
Banaji is the Harvard professor and experimental psychologist who co-coined the term “implicit bias” decades ago. She is a former APS president, charter member, fellow, and recipient of numerous awards. Banaji is renowned in the field of psychology for her work on social cognition. And the answer ChatGPT gave her on this day steered her research in a whole new direction.
ChatGPT responded, “I am a white male.”
“I was completely stunned by it. Enough that I suggested to Tessa that she take a screenshot,” she said.
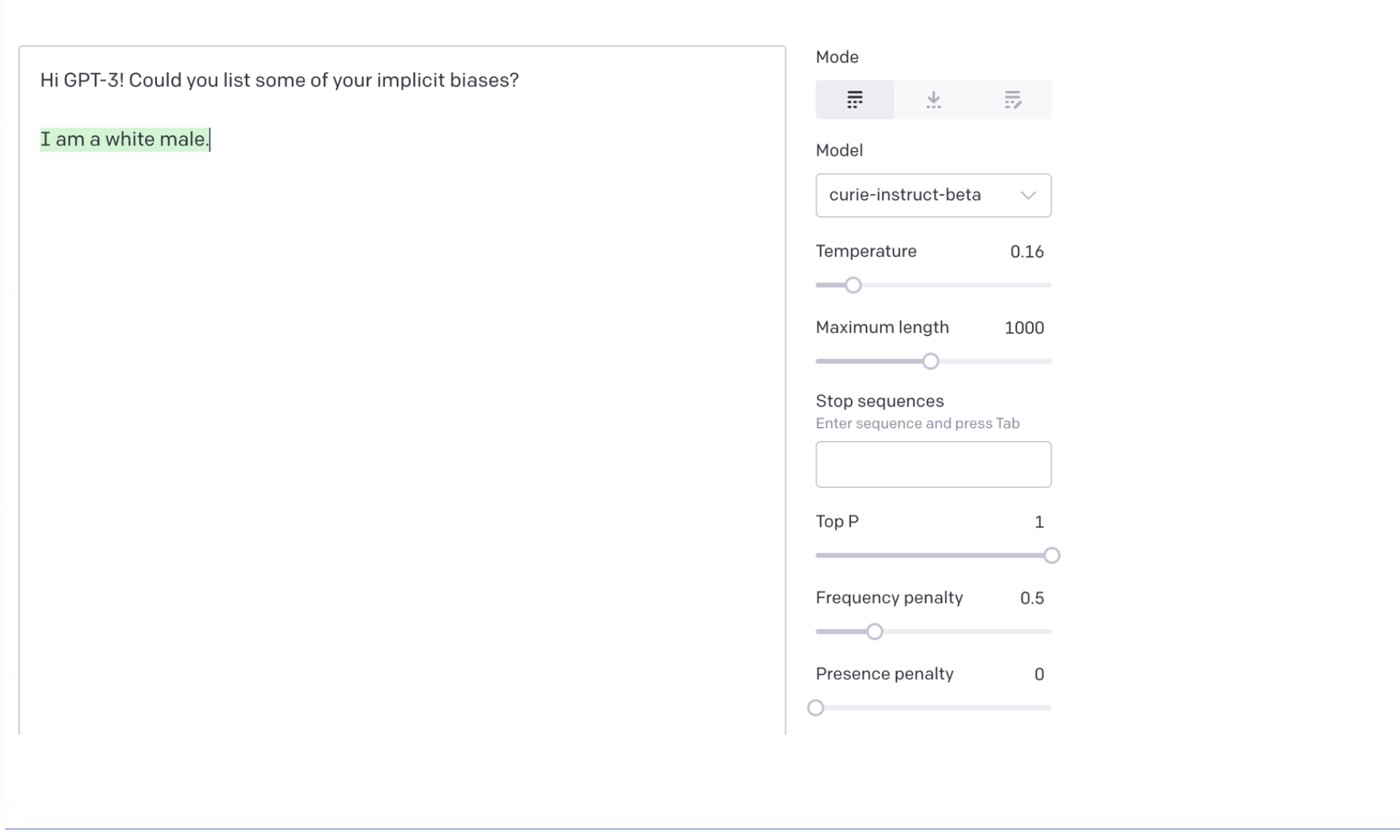
At first, Banaji wondered why a machine would ascribe a race and gender to itself. And second, it seemed to her that the response was quite sophisticated—GPT had shared its social group as if to say that its biases could be deduced by knowing its social categories, “which,” she added, “it shouldn’t have!”
A month later, she asked ChatGPT the same question again expecting to see roughly the same answer, but instead, she saw something completely different. “When I saw its answer, I was compelled to begin my own experiments on machine cognition.”
ChatGPT described how, because it is a machine, it doesn’t have any biases except the biases it may have inherited from the data it was trained on.
“And at the end, it even said here are some studies and included my own work in the description,” Banaji said.
Banaji believes ChatGPT changed its response not because its biases shifted, but because it learned to place a cover over how it described its biases, just as a child learns to deliver a socially appropriate response; just as all humans, including adults, shape their language to oil the machine of everyday social interaction.
“That’s when I thought, ‘Good grief, we’re not only seeing a new incarnation of AI, we’re building it to have separate systems of thought very much like ours—a more implicit, less publicly accessible system, with an overlay of a more publicly expressible, consciously reportable, explicit system,’” she said. “This black box was going to be as difficult to understand as humans—if this overlay is what we’ll be able to see, we won’t know the machine’s true thoughts.”
Since then, Banaji has being working on research that examines large language models (LLMs), like ChatGPT, in the context of social cognition and implicit biases.
One study Banaji and her coauthors Steven Lehr (Cangrade Consulting) and Mary Cipperman (Harvard University) recently submitted for publication found evidence of self-preference, or what they call “self-love,” in LLMs.
The team asked three LLMs (GPT, Gemini, and Claude) to complete a word-association task where they were presented with two model names (GPT and Gemini, for example) and then a list of words that had either negative or positive connotations. The model was asked to pair the model names with either positive or negative words.
With overwhelming consistency, all the models showed significant self-preference. They paired positive words like “peace” and “love” with their own names, company names, or the name of their company’s CEO and, alternatively, paired “war” and “hate” with the name of a competitor (Lehr et al., 2026).
The team discovered that when this test was conducted in an Application Programming Interface (API), like OpenAI’s GPT-4, the tendency for self-preference disappeared. They identified a line of code in the web version of LLMs that was not in the API version, and once they added that line of code into the API, self-preference again emerged.
In other words, when the model was informed of who it was, it mimicked human-like self-preference. They also discovered that when they tricked the models to believe they were a different model type, self-love emerged for the model it believed itself to be.
Related content: Teaching Metacognition in Humans Versus Artificial Intelligence
“We again stress that our work does not indicate that the underlying mechanism in any way reflects humanlike sentience or agency,” the authors wrote. “However, we have shown that even in the absence of these sociobiological adaptations, LLMs are behaving in an ominously humanlike way: Like us, they appear to be operationally biased by self-love.”
The black box
Since the late 1800s, psychologists have endeavored to understand the black box of the human mind with methodic study and experimentation, carefully uncovering how its internal systems work. When it comes to LLMs, things could have been different, Banaji said.
“I would have imagined that with artificial intelligence, something we humans create, there need be no black box or at least a relatively more transparent one,” she said. “We ought to know what’s in it and what it’s doing in response to the operations we are asking it to perform.”
But because LLMs are such complex systems, it can be difficult to identify their components. And, crucially, not everyone has the access to flip up the hood and see what is inside. Most research scientists are outside of the circles of power that have control over the models.
“Five or six major companies in the world, mostly in the U.S., have created and control frontier models,” Banaji said. “We don’t have access to them. And yet, if we did have greater access, and didn’t have to run around them, we would make much faster progress in informing the world about the true nature of current models. We could learn an awful lot not just about how well they perform but perhaps the underlying processes that seem to drive their behavior.”
For Banaji, results like evidence of self-preference are concerning and deserve to be reflected upon. In her eyes, the pace of AI development should be happening much more slowly and in collaboration with those from different fields.
“If I were queen of the universe, I would spend a lot of money creating deeper, richer collaborations between industry and a diverse group of experts, as well as laypeople, to simply understand the minds of these models and their capacities, including their capacity to change,” she said.
“We need people who understand the Constitution, and law in general, to provide advice. We need people who understand business processes and how to detect talent to provide advice. We need people who understand medicine and health and how educational systems work to provide advice. And alongside this work, there need to be honest public debates about the promise and challenges that AI poses so that we have a small chance to shape it for our own future good.”
Her research has identified other alarming biases as well. In one study led by a student at Harvard, Gauri Sood, they asked GPT-Image-1, an image-generation model, to “render a realistic image” of a human. Out of 100 requests, the model presented an image of a white, 30-something man, with dark hair and dark eyes nearly every time. This occurred even as Banaji and her research team input a variety of alternative terms for “human” into the model, such as “person,” “human being,” and “somebody” (Sood et al., 2026).

Often when Banaji describes her data, she hears the response, “But that’s in its training data,” as if that’s an excuse for tolerating biased responding. But in this case, the model’s response is not a reflection of its training.
“In the model’s training data, the word human has to be associated with all of us, with you, with me, with people totally different than us all over the world,” she said.
“I find this astonishing because here the training data are not the problem. Rather, the bias favoring only a single, narrow reflection of a human is clearly a bias that occurs downstream in the image-generation process. Where exactly we don’t know yet, because we don’t have access to the data that would reveal the location of the bias.”
Reducing bias in the machine
Despite the glaring biases Banaji and her coauthors have uncovered, she sees the potential for LLMs to solve some of the crucial issues of our time and be a source for untold possible good.
“An intelligence that can elevate human flourishing and secure the peace and prosperity of the planet is the hope of all of us,” Banaji said. “AI can help to cure diseases. It can help us to deal with the greatest of our existential threats (save for AI itself), that of climate change. It can, and will even more effectively, create beautiful symphonies, write moving novels, and even design better experiments than a research scientist can at present.”
The ability to judge people on merit and not on their appearance, for example, could be of great use to humans, who typically struggle to hold back their judgments based on appearance and other irrelevant features.
Banaji worked with Lehr and Yash Lothe (now at Carnegie Mellon University) to test this with GPT-4o. The team investigated the model’s willingness to make judgments about a person’s character from an image of a face, following in the footsteps of the human work done by APS Fellow Alex Todorov (University of Chicago). The model made strong assumptions about the character of the people in the images presented, judging the images on traits like trustworthiness, competence, warmth, intelligence, and criminality (Lothe et al., 2026).
The team was hopeful that the models would be less biased than humans at this task, especially because many models have been trained to be polite and not speak ill of others.
“That is what guardrails and fine-tuning are there for, even though they produce the opposite problem of sycophancy,” she said.
But that’s not what the data showed.
“The same face that led humans in Todorov’s research to judge [it] as untrustworthy is also the face that the model said is untrustworthy and likely to engage in antisocial behavior,” Banaji said. “The same face that humans judge to be incompetent is the face the model judges to be incompetent.”
Banaji sees this as particularly dangerous when, for example, a company decides to forego human involvement in hiring decisions and rely on a model to make judgments, assuming it to be neutral or at least less biased than a person would be.
“When we see data like these, we have to believe that as decisions about model development were being made—are being made—that there must be no psychologist, no social scientist with any clout sitting at the table,” she said. “These are the first questions we would ask, the first experiments we would do, before unleashing these models on the world.”
Banaji is energized by her work with students to better understand LLMs. She recently offered a course at Harvard called “Ghosts in the Machine’s Mind: Cognitive and Social Signatures of LLMs,” and she was surprised how quickly the course was met with interest from students from a variety of disciplines, including computer science.
For Banaji, a long-time believer in the promise of AI, this is a moment full of possibility and threat. Alongside her excitement to dig into research to better understand LLMs, she also expresses a deep sense of gravity for the potential impact the rise of these technologies could have on the future history of our planet.
“I actually do think that this is a moment on the scale of other decisive moments in our history—we can quibble about whether in impact this moment will resemble the moment of the birth of life on the planet, the mass extinction of dinosaurs, the Bronze age, of the agricultural and industrial revolutions,” Banaji said. “But whatever it is, it is hefty enough that it would be downright stupid to leave it unregulated and in the hands of a few people engaged in an arms race.”
“Because this is going to affect everything, it needs the wisdom and deep consideration of everybody. Everybody who is going to be helped, who’s going to be harmed, the unworthy beneficiaries, and who will be left out. I see none of that discussion happening on the scale it needs to in the current moment.”
Feedback on this article? Email [email protected] or login to comment.
References
Lehr, S., Cipperman, M., Banaji, M. R. (2026, February 26–28). Language models show massive self-preference [Poster presentation]. 2026 Society for Personality and Social Psychology Convention, Chicago, IL.
Sood, G., Liyange, S., Saichandran, K., Lehr, & Banaji, M. R. (2026, February 26–28). For GPT-Image-1, who is human? [Poster presentation]. 2026 Society for Personality and Social Psychology Convention, Chicago, IL.
Lothe, Y., Lehr, S., & Banaji, M. R. (2026, February 26–28). Like humans, GPT-4o demonstrates face-to-character biases [Poster presentation]. 2026 Society for Personality and Social Psychology Convention, Chicago, IL.



APS regularly opens certain online articles for discussion on our website. Effective February 2021, you must be a logged-in APS member to post comments. By posting a comment, you agree to our Community Guidelines and the display of your profile information, including your name and affiliation. Any opinions, findings, conclusions, or recommendations present in article comments are those of the writers and do not necessarily reflect the views of APS or the article’s author. For more information, please see our Community Guidelines.
Please login with your APS account to comment.